Samyak Rawlekar
I am a PhD student in the Computer Vision and Robotics Laboratory at the University of Illinois Urbana-Champaign. I am advised by Prof. Narendra Ahuja.
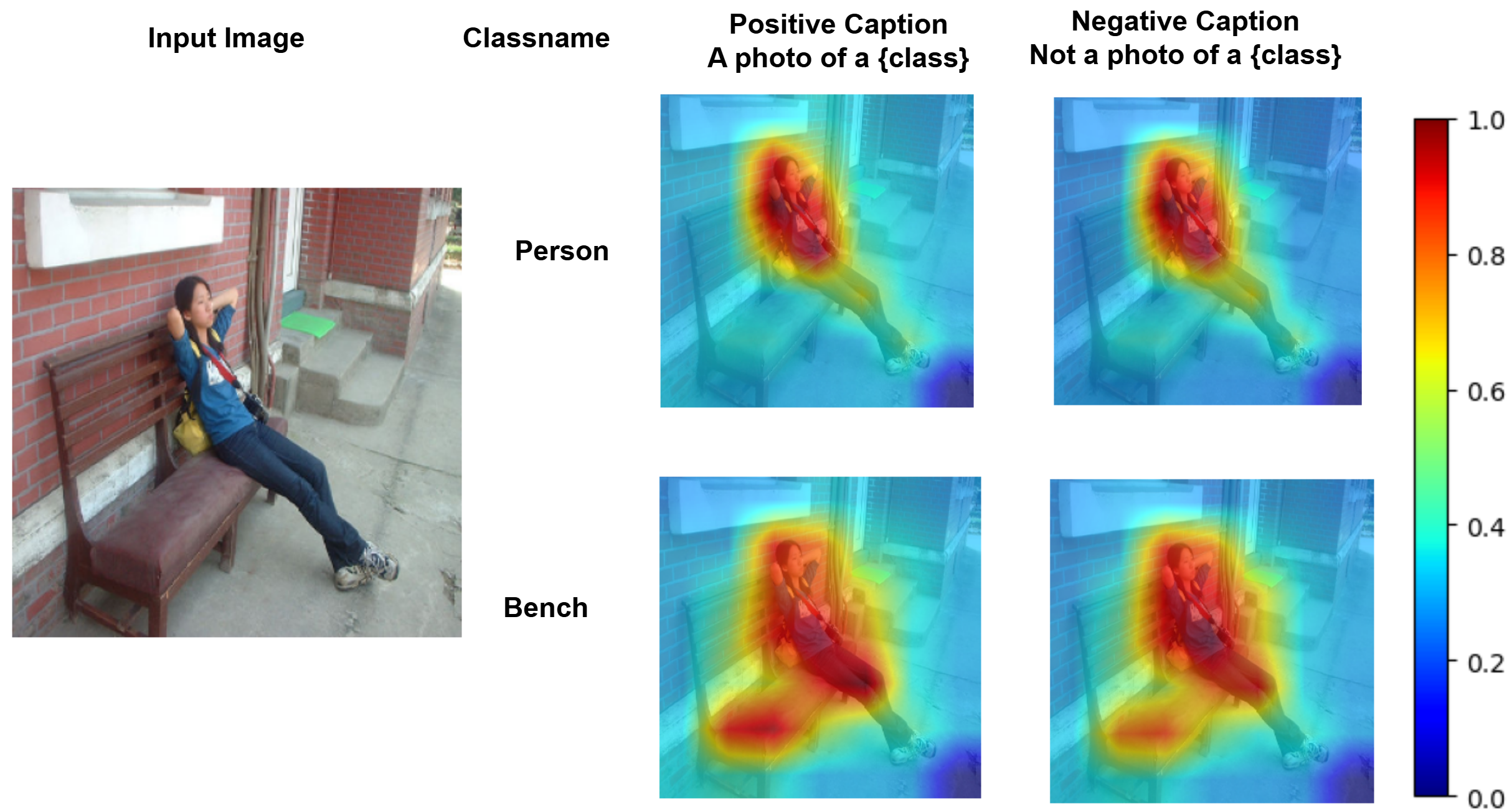
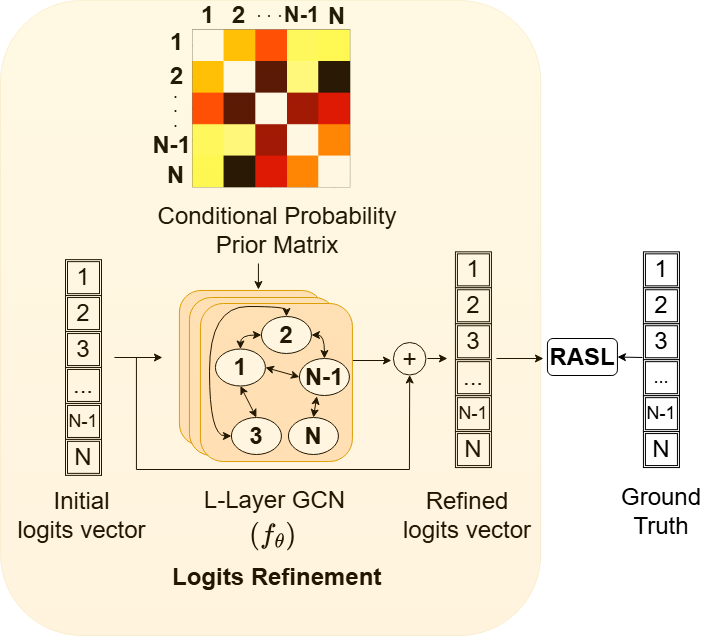
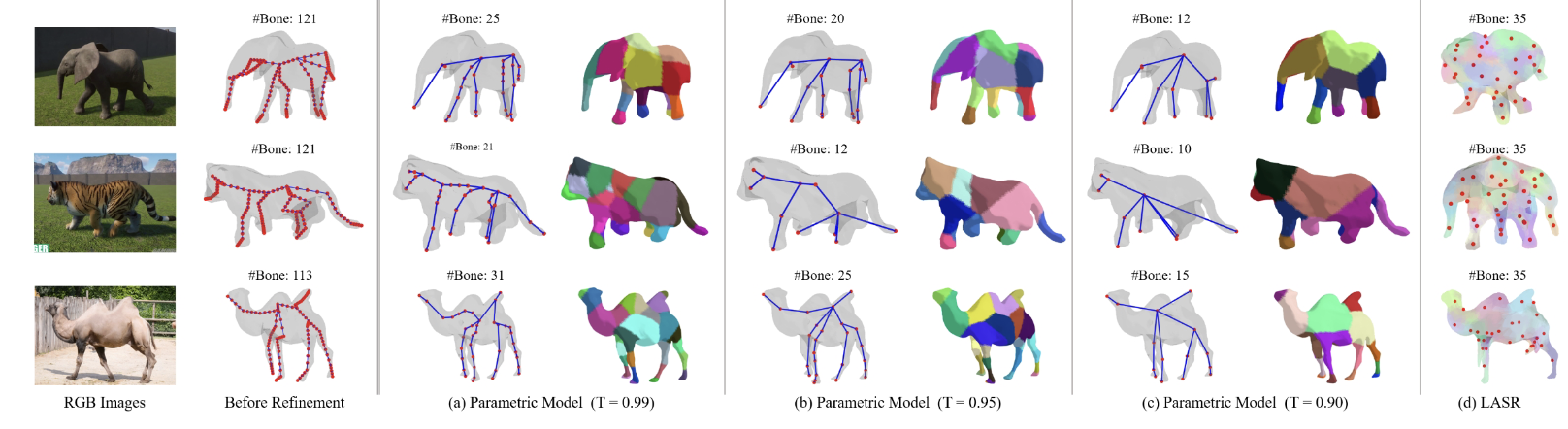
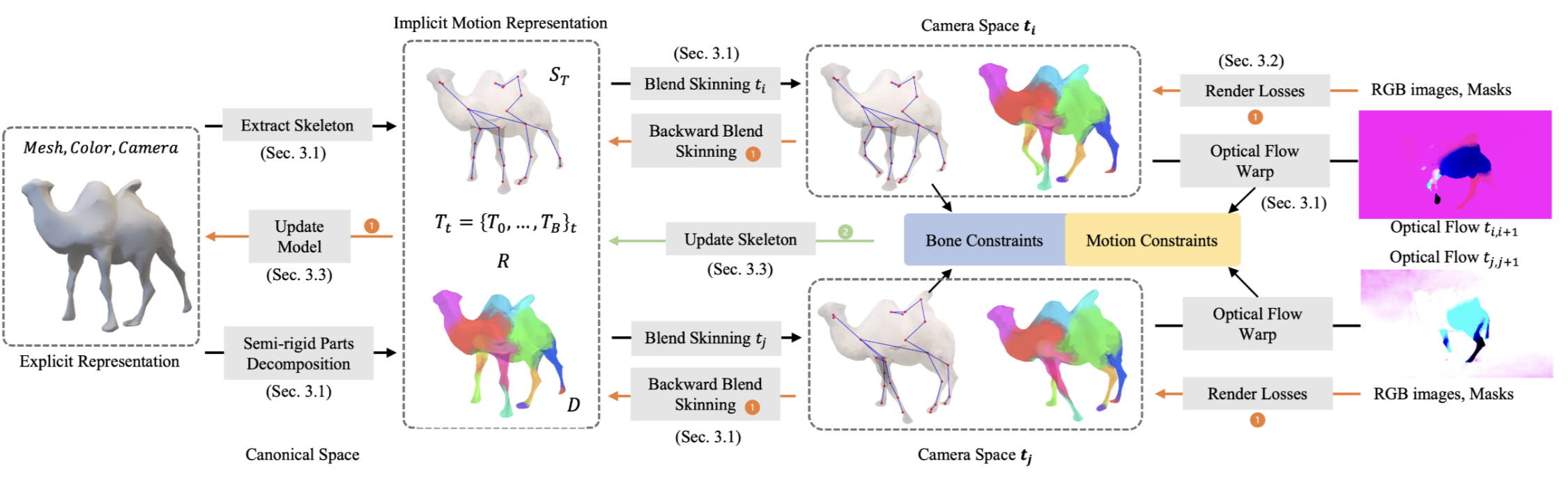
I love pixels and have recently been integrating them with text to solve intricate and exciting problems in Computer Vision. Particularly, I focus on using large multi-modal (vision-language) models for multi-task learning.
Previously, I obtained MS in Computer Engineering from New York University, and B.Tech in Electrical Engineering from IIT Dharwad.